Written by Isla Gladstone, Senior Curator Natural Sciences, Bristol Museums
On 13th March I travelled to Sofia in Bulgaria, my mind buzzing with questions about biodiversity data…
I had been awarded one of 30 funded places on the first training school of Mobilise, an EU initiative to mobilise data, experts and policies in scientific collections. More specifically, Mobilise is an EU COST Action: a bottom-up network funded over four years to boost research, innovation and careers by COST, an intergovernmental framework for European Cooperation in Science and Technology.
Digitisation and data management challenges in small collections promised new skills in the key basics of data quality and cleaning. It also offered a chance to meet colleagues from around the world, and connect to a bigger picture.
At a time of unprecedented human-caused climate change, biodiversity loss and environmental degradation, it feels more urgent than ever to connect museum collections to real-world change. Natural sciences collections offer precious opportunities here. Alongside huge potential to engage communities and inspire debate, specimens are unique sources of the scientific evidence urgently needed to unlock sustainable development solutions:
“There is more information about biodiversity in [the world’s] natural sciences collections than all other sources of information combined.” iDigBio

Collections’ biodiversity data: the what, when, where, who collected attached to many biological and palaeontological specimens © Bristol Museums
But very few UK institutions are currently able to contribute to the type of global-level collections research that may have most impact here: that are made possible by digital technologies and ‘free and open access’ data aggregators like the Global Biodiversity Information Facility (GBIF).

GBIF: the Global Biodiversity Information Facility (website front page, accessed 7 May 2019) © GBIF
With custody of rich and historic world material due to our history of collecting, we need to be doing more. The team at Bristol Museums have been supported by the John Ellerman Foundation to start to overcome technical, infrastructure, resource and skills barriers familiar to many, with help from iDigBio and the Natural History Museum London. Our goal is to share Bristol’s data, but also our approach. We want to help inform an emerging UK infrastructure inclusive of small and regional collections, and their valuable opportunities for impact. The skills and connectivity offered by the Mobilise workshop were an important part of this journey.
Workshop Day 1
A strategy
After a welcome by our hosts from the Bulgarian Academy of Sciences, and course leader Dr Catherina Voreadou, day 1 kicked off with a game. 59 trainees worked in small groups to devise an institutional digitisation strategy, based on a fictional scenario. Sifting and allocating cards got us thinking about our goals. What tasks, resources, stakeholder groups and workflows are required to achieve these? Whatever level you are working at, having a strategy in place is crucial to realising a bigger goal.

Course activity: Plotting an institutional digitisation strategy © Bristol Museums
An introduction to GBIF, data quality & cleaning
A series of talks then grounded us in key topics. In the spirit of an open community, these were based on existing resources developed by GBIF.
Piotr Tykarski, University of Warsaw, gave us an overview of GBIF. This holds taxonomic, specimen, literature and fieldwork data in four major classes. Darwin Core is an international standard that facilitates sharing of data with aggregators like GBIF. It’s a “list of fields and their definitions, as they relate to biodiversity data” (GBIF). Your in house database might give a name and format to a piece of data that is different to someone else’s. Mapping it to Darwin Core means everyone can interpret it.
Elspeth Haston from the Royal Botanic Garden Edinburgh talked about data quality, in the context of biodiversity informatics. Is your data fit for the purpose you intend it? Is it fit for a user’s needs? For example, one researcher may require very precise geographic coordinates, but for another country is enough. What’s important is that you convey key metadata, so they can decide.

Course slide: Fitness for use © GBIF
We were also reminded:
“All data include error – there is no escaping it! It is knowing what the error is that is important, and knowing if the error is within acceptable limits for the purpose to which the data are to be put.” (Chapman 2005).
Correctness (accuracy) and consistency (precision) are two ways of documenting data error to provide measures of quality. Once you have identified inaccuracies and imprecisions in your data, cleaning can improve its fitness for use.
“Data cleaning is the process of correcting or removing dirty data caused by contradictions, disparities, keying mistakes, missing bits, etc. It also includes validation of the changes made, and may require normalization” (GBIF).
Dimitri Brosens from the Belgian Biodiversity Platform shared tips and principles including: use existing standards; use the right tools; have a Data Management Plan; prioritise: 90% of effort is in the last 10%.

Course slide: Data cleaning principles © GBIF
Tools #1: Excel and Open Refine
All delegates had been asked to bring a laptop, samples of our institution’s biodiversity data, and to download some free open source software. We tried out some simple data manipulation in Excel: filtering into ascending or descending lists to help spot data error; merging or splitting columns and changing cell formats to help standardise for export.
Heimo Rainer, NHM Vienna, introduced us to Open Refine: “A powerful tool for working with messy data” (GBIF). This seems like a dream tool for cleaning and standardising data – offering multiple filters to bring up a big picture overview, bringing together similar data for easy bulk editing, and even offering an option to reconcile your data with an outside database, e.g. taxonomic names.
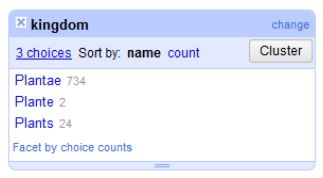
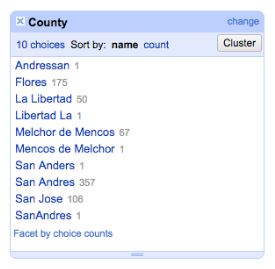
Open Refine: giving a big picture overview and helping spot inconsistency and error © GBIF
You can download Open Refine for free: http://openrefine.org/download.html
National Museum of Natural History, Sofia
After a day packed with content, we were treated to a guided tour of the wonderful National Museum of Natural History which is the oldest and richest of its kind on the Balkan Peninsula, founded in 1889.

National Museum of Natural History, Sofia © Bristol Museums
Workshop Day 2
Greg Riccardi, one of the principal investigators of iDigBio.org, switched our focus to one of the key factors in achieving quality data: people! If you don’t consider people’s needs, getting their buy in and making processes work for them, you won’t achieve a quality output.
Tools #2: QGIS
QGIS is free and open source geographic information system software. In this context, we used it to help identify data error. For example, plotting geographic coordinates on a map easily highlights a terrestrial occurrence that plots in the sea, or vice versa.
You can download QGIS here: QGIS 3.4 Madeira with some plugins such as GBIF occurrences
Publishing and practice
We finished the workshop with a look to future technologies, uses of data, and case studies of what you can achieve with clean data.
Christos Arvanitidis, Head of the Biodiversity Laboratory Greece, showed us some amazing micro-CT images and highlighted the potential future of the ‘cybertype’.
Why do you want to publish your dataset? Donat Agosti, founding president of Plazi Switzerland, shared the importance of linking data to the information published about it. This includes making sure data in scientific publications is findable, citable and reusable, and ideally shared with GBIF.
Inspiring case studies of successful data sharing using different approaches came from: Quentin Groom, Meise Botanic Garden and Elspeth Haston, Royal Botanic Gardens Edinburgh
Becoming part of the open data community
The new skills and learning from this course, backed up by my Europass certificate, are already proving very useful. But one of the biggest things I took away was a new connection to an open and supportive data community. All the speakers were experts in their fields, but only too happy to talk through my very entry level questions. At a politically difficult time for the UK, and with big global biodiversity challenges but low museum resource, this collaborative approach is something to treasure.
For future opportunities for grants, training etc., take a look at the Mobilise website. The course leaders also highlighted Biodiversity_Next as a major upcoming opportunity. This conference in Leiden in October 2019 will bring together major international organisations, research scientists and policy makers to explore challenges and opportunities in data-intensive bio- and geodiversity research. NatSCA are also planning an ‘Introduction to Mobilising your Biodiversity Data’ workshop – so keep eyes peeled!
Mobilise: funders and linked infrastructure
Huge thanks to COST, Mobilise, the course leaders and trainers for this valuable opportunity.


Pingback: Our Top Ten Blogs of 2019 | NatSCA